Documentação
Apresentação
Este projeto apresenta uma solução completa que inclui uma API que serve como um serviço de backend para extrair, processar e analisar dados do pregão da B3. Esses dados são enviados a um bucket S3 em formato parket, processado com AWS Glue e disponibilizados no AWS Athena.
A solução da API está disponível no GitHub do desenvolvedor: API Pregão B3 no GitHub E para acessar a API em produção entre em http://tech-challenge-rodrigo.sa-east-1.elasticbeanstalk.com/. Conforme indicado pela URL, a API está hospedada no AWS Elastic Beanstalk.
Os dados retornados pela API são obtidos através de scraping ou em caso de falha desse, via um endpoint descoberto ao analisar as requisições feitas pelo site da B3. No caso de scraping, o mesmo é feito utilizando a biblioteca playwright que executa a ação no momento da requisição.
1. Introdução
Através dessa documentação voce será apresentado ao código da API, configurações de cada recurso da AWS e arquitetura do projeto.
2. Motivação
O desenvolvimento dessa solução visa atender ao Tech Challenge Fase 02 do curso de Machine Learning Engineering da FIAP.
3. Requisitos
- Scrap de dados do site da B3 com dados do pregão.
- Os dados brutos devem ser ingeridos no s3 em formato parquet com partição diária.
- O bucket deve acionar uma lambda, que por sua vez irá chamar o job de ETL no glue.
- A lambda pode ser em qualquer linguagem. Ela apenas deverá iniciar o job Glue.
- O job Glue deve ser feito no modo visual. Este job deve conter as seguintes transformações obrigatórias:
- agrupamento numérico, sumarização, contagem ou soma.
- renomear duas colunas existentes além das de agrupamento.
- realizar um cálculo com campos de data, exemplo, poder ser duração, comparação, diferença entre datas.
- Os dados refinados no job glue devem ser salvos no formato parquet em uma pasta chamada refined, particionado por data e pelo nome ou abreviação da ação do pregão.Tech Challenge
- O job Glue deve automaticamente catalogar o dado no Glue Catalog e criar uma tabela no banco de dados default do Glue Catalog.
- Os dados devem estar disponíveis e legíveis no Athena.
- É opcional construir um notebook no Athena para montar uma visualização gráfica dos dados ingeridos.
4. Arquitetura Geral
A arquitetura geral da solução é apresentada na imagem a seguir. Ela contempla o fluxo de dados desde o scraping no site da B3, passando pelo armazenamento no S3, processamento no Glue e disponibilização no Athena.

5. Solução Desenvolvida
O scrap de dados, formatação dos mesmos em formato parquet e envio para um bucket S3 na AWS estão cobertos pela API desenvolvida em .NET 9.0. O fluxo completo pode ser iniciado manualmente através de um post para o endpoint /api/ExecutePipeline . Para facilitar o controle, foi desenvolvido também um job no EventBrigde responsável por disparar diariamente uma função Lambda que faz a requisição a esse endpoint. Assim que os dados são processados pela API e enviados para o bucket S3, o mesmo foi configurado para disparar um job ETL Glue através de uma função lambda feita em Python e apresentada na seção "Configurações AWS" da Documentação.
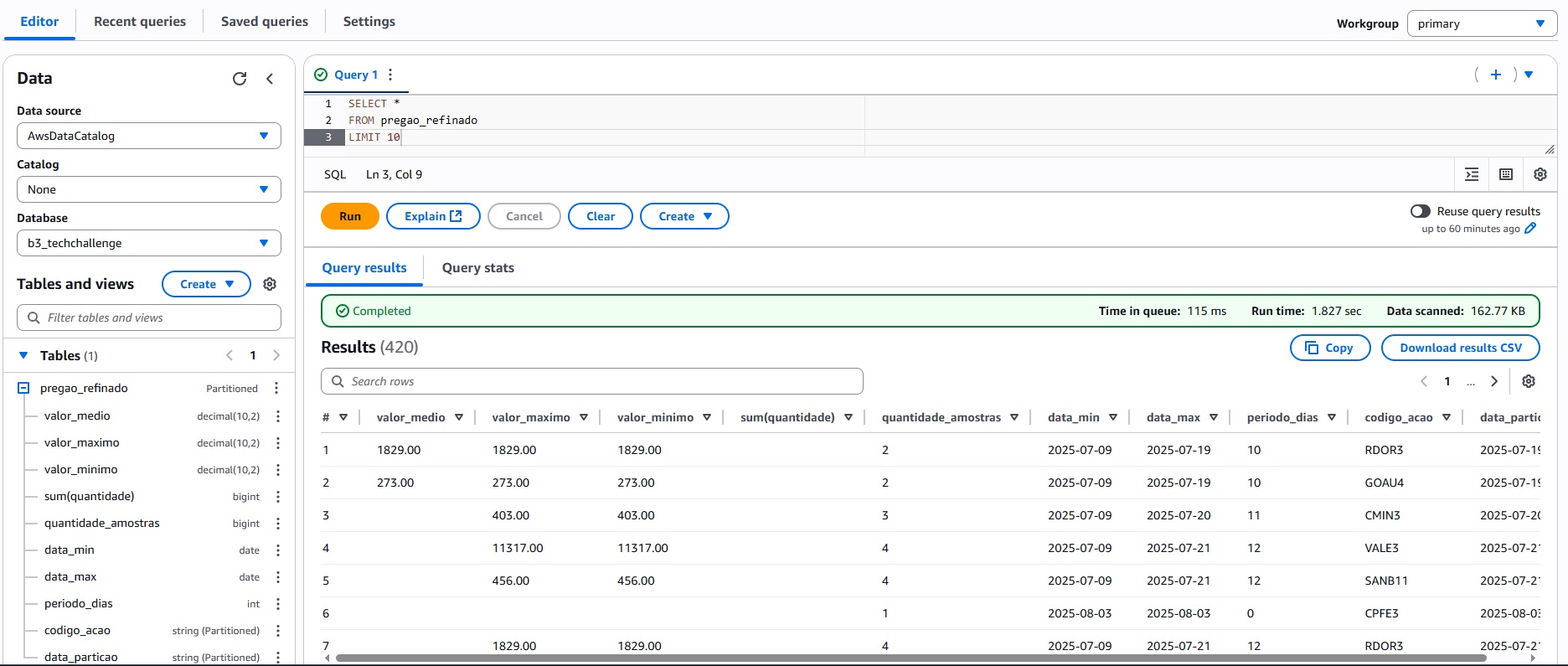
Foi feito um job ETL no Glue através do modo visual executando diversas transformações, conforme imagem a seguir.
Em resumo esse job ETL Glue executa os seguintes passos:
- Os arquivos parket são obtidos do bucket S3, através do "Data Source"
- Ocorre o renomeamento de algumas colunas através do "Change Schema".
- Uma coluna com o ano é derivada a partir da data, usando uma expressão SQL, através do "Dynamic Transform".
- Os dados foram agrupados pelo código da ação e os valores agregados médio, máximo,mínimo, somatório e contagem dos valores foram realizados através do "Aggegate".
- Essas colunas agregadas também foram renomeadas através do "Change Schema".
- Foi gerada uma coluna derivada de subtração de duas datas para gerar um período em dia, usando uma expressão SQL, através do "Dynamic Transform".
- Foi gerado mais uma coluna derivada para classificar cada partição, tomando como base a data na qual o dado entra no bucket, usando o "Dynamic Transform"
- Por fim, os dados refinados foram salvos em formato parquet no bucket S3, através do "Data Target".
O equivalente código Python dessa configuração que foi feita de maneira visual também está disponível na seção "Configurações AWS" da Documentação para avaliação de maiores detalhes ou replicação caso necessário.
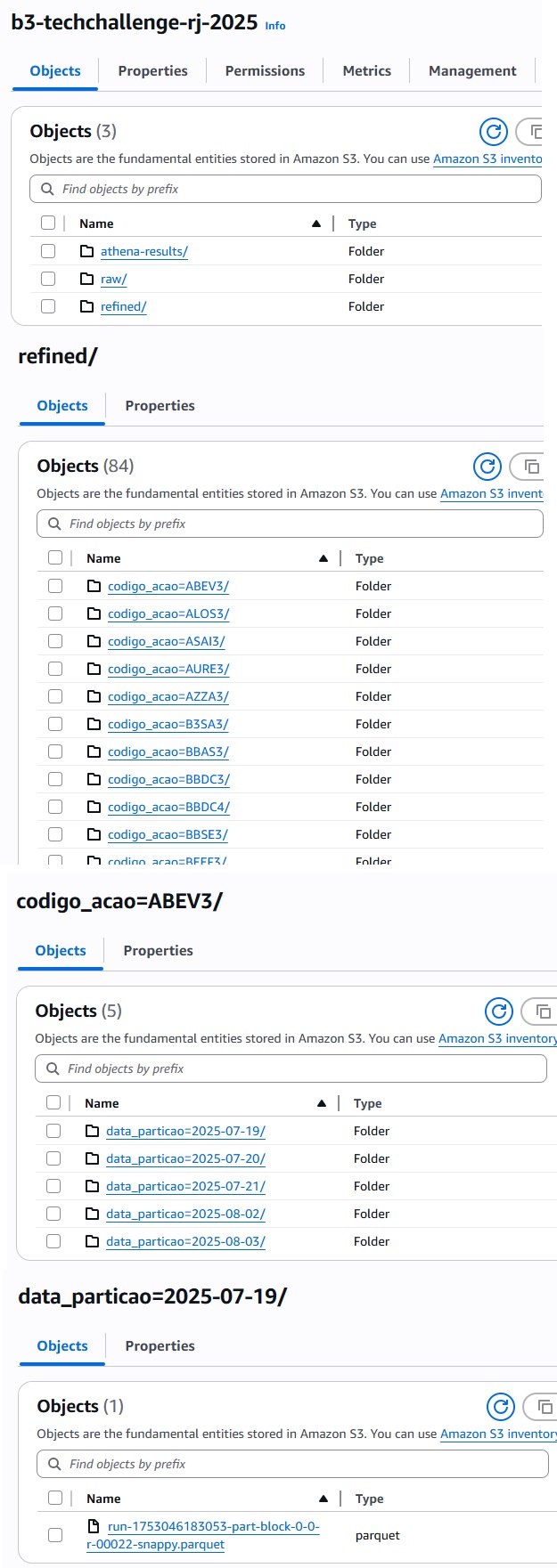
Os dados refinados no job glue são salvos em formato parquet em uma pasta chamada refined, particionado por data e pela abreviação do pregão. Na imagem a seguir, apresento a estrutura dos dados salvos no bucket S3, focando na pasta refined.
Os dados são automaticamente catalogados no Glue Catalog e estão disponíveis no Athena, conforme imagem a seguir.